
In den vergangenen Jahren hat sich die künstliche Intelligenz (KI) zu einem bahnbrechenden Instrument entwickelt, das nahezu alle Branchen revolutioniert. Immer mehr Unternehmen setzen auf KI, um Prozesse zu automatisieren, Effizienz zu steigern und innovative Lösungen zu entwickeln. Ob es darum geht, komplexe Softwareprozesse zu optimieren, innovative Lösungen für Anwendungen zu entwickeln oder KI-Assistenten direkt in die Software zu integrieren – Künstliche Intelligenz ist mittlerweile zu einem entscheidenden Bestandteil der modernen Software geworden.
In diesem Blogbeitrag schauen wir genauer darauf, wie uns die Einbindung künstlicher Intelligenz ermöglicht hat, die automatisierte Ticketgenerierung in unserer Projektmanagement-Software umzusetzen.
Idee
Die Ticketgenerierung mit Redmine, unserem Projektmanagement Tool, soll durch die Implementierung von KI erweitert werden, sodass dadurch, automatisiert, Tickets generiert werden können. Durch diese Umsetzung sollen erste Erfahrungen mit KI und deren Integration gesammelt werden.
Was ist Redmine?
Redmine ist eine Open-Source-Plattform für Projektmanagement und -verfolgung. Die Software ermöglicht es Teams, Projekte zu planen, Aufgaben zuzuweisen, Fortschritte zu überwachen und Zusammenarbeit zu fördern. Redmine bietet Funktionen wie Gantt-Diagramme, Kalender und Zeitverfolgung.
Backend Umsetzung
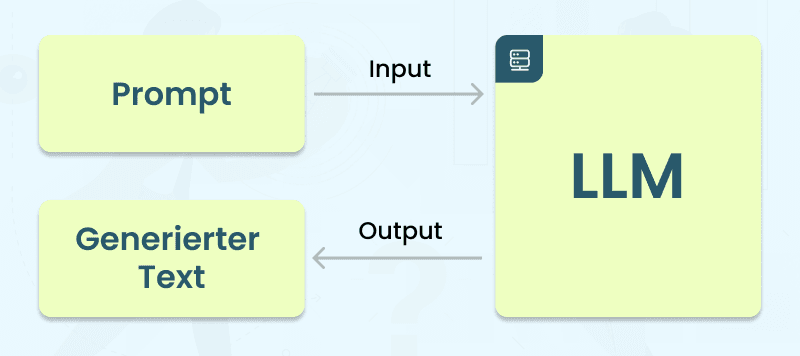
Im Backend kommt ein Large Language Model (LLM) zum Einsatz, um eine innovative Lösung für die automatisierte Ticketgenerierung zu bieten.
Was ist ein LLM?
Ein "Large Language Model" (LLM) bezieht sich auf ein umfangreiches Sprachmodell, das entwickelt wurde, um natürliche Sprache zu verstehen und zu generieren. Diese Modelle basieren oft auf künstlicher Intelligenz und maschinellem Lernen und sind darauf ausgelegt, komplexe sprachliche Zusammenhänge zu erfassen. LLMs werden in verschiedenen Anwendungen eingesetzt, darunter maschinelles Übersetzen, Textgenerierung, Frage-Antwort-Systeme und mehr. Ein bekanntes Beispiel für ein LLM ist GPT, ein Sprachmodell, das von OpenAI entwickelt wird.
Hugging Face
Hugging Face ist eine Plattform, die sich auf künstliche Intelligenz und maschinelles Lernen im Bereich der natürlichen Sprachverarbeitung (NLP) konzentriert. Die Website bietet eine Fülle von Ressourcen und Tools für Entwickler und Forscher, die an NLP-Projekten arbeiten. Hugging Face ist besonders bekannt für sein Modellhub, in dem eine breite Palette von vortrainierten Sprachmodellen verfügbar ist, darunter sind z.B. Modelle für Übersetzung, Textgenerierung und Klassifizierung.
Da in diesem Fall für die Ticketgenerierung nur ein Modell benötigt wird, welches Text generiert, wurde sich für das EM German Modell entschieden, welches eine Mischung aus den großen Open-Source Modellen ist und auf einem deutschen Datensatz trainiert wurde. Für dieses Modell gibt es ein Template, um das Verhalten des LLMs zu definieren:
Du bist ein hilfreicher Assistent. USER:
ASSISTANT:
Die <instruction> entspricht dem Input des Benutzers. Dieses Template kann jedoch beliebig und individuell erweitert werden. Mehr dazu im Abschnitt Modelfile.
Ollama
Um nun das LLM ausführen zu können, nutzen wir Ollama, ein Open-Source Framework. Ollama ermöglicht die Ausführung von LLMs direkt auf dem eigenen Computer. Darüber hinaus bietet das Framework auch eine benutzerfreundliche REST-API an, wodurch Entwickler auf einfache und schnelle Weise mit dem Modell kommunizieren und es nahtlos in die eigene Software integrieren können. Hat man z.B. in Ollama das vorher genannte LLM importiert, dann kann man über einen POST Request mit dem Modell kommunizieren. Dafür gibt man der Anfrage ein JSON mit den entsprechenden Daten mit.
Dazu ein Beispiel:
{ "model": "ai_assistant", "prompt": "Was ist ein LLM?", "stream": false }
{
"model": "ai_assistant",
"prompt": "Was ist ein LLM?",
"stream": false
}Hier wird das Modell definiert, welches man ansprechen will, den Prompt bzw. Input und ob die Response als Stream zurückkommen soll.
Daraufhin hat das LLM folgenden Output generiert:
LLM steht für "Large Language Model" oder großes Sprachmodell. Es handelt sich um ein maschinelles Lernmodell, das auf einem riesigen Datensatz von Texten trainiert wurde. Das Modell lernt dabei die Muster und Strukturen der Sprache zu verstehen und kann basierend auf den gegebenen Eingaben antworten.
Modelfile
Modelfiles spielen eine entscheidende Rolle bei der Anpassung und Nutzung des Sprachmodells. Damit können Feinabstimmungsparameter festgelegt werden, um das Verhalten zu beeinflussen und das Template des LLMs kann nach Bedarf angepasst werden. Dies ermöglicht es, einen vordefinierten Prompt zu definieren, um das gewünschte Verhalten präzise zu beschreiben.
In unserem Falle sieht der Prompt kurzgefasst und abstrakt in etwa so aus:
Deine Aufgabe besteht darin, eine ausführliche Ticketbeschreibung für unser Softwareunternehmen zu generieren. Dabei soll der gegebene Kontext genutzt und ein festes Schema befolgt werden.
Nach dem Senden einer neuen Anfrage an das LLM generiert es nun mithilfe des vordefinierten Prompt-Templates die gewünschte Ticketbeschreibung.
Die zu bewältigenden Aufgaben für das LLM wurden in Einzelschritte unterteilt, was die Qualität der Ergebnisse deutlich verbessert. Die Struktur der Ticketbeschreibung wurde in Titel, Beschreibung und Klassifizierung aufgesplittet. Jeder dieser Teilaufgaben ist einem eigenen Modelfile mit spezifischen Parametern zugeordnet. Um eine vollständige Ticketbeschreibung zu generieren, werden diese Einzelschritte einfach in einer Pipeline nacheinander ausgeführt, um das gewünschte Gesamtergebnis zu erzielen.
Frontend Umsetzung
Um das LLM in unsere Software zu integrieren, ist im Frontend eine Benutzeroberfläche erforderlich. Diese UI soll eine einfache Kommunikation mit dem LLM ermöglichen. Inspiriert von der einfachen Handhabung und Benutzerfreundlichkeit von ChatGPT, habe ich ein ähnliches UI entworfen.
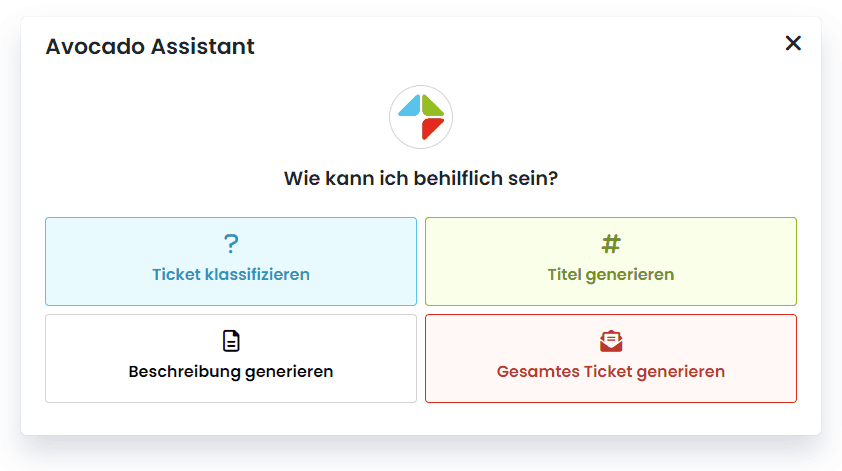
Avocado Assistant
Für die Darstellung des Assistenten wurde ein schlichtes Modal verwendet, das für jede Teilaufgabe einen separaten Chat beinhaltet. Dies ermöglicht eine klare Kommunikation mit dem Assistenten und bietet eine übersichtliche Darstellung der generierten Ergebnisse.
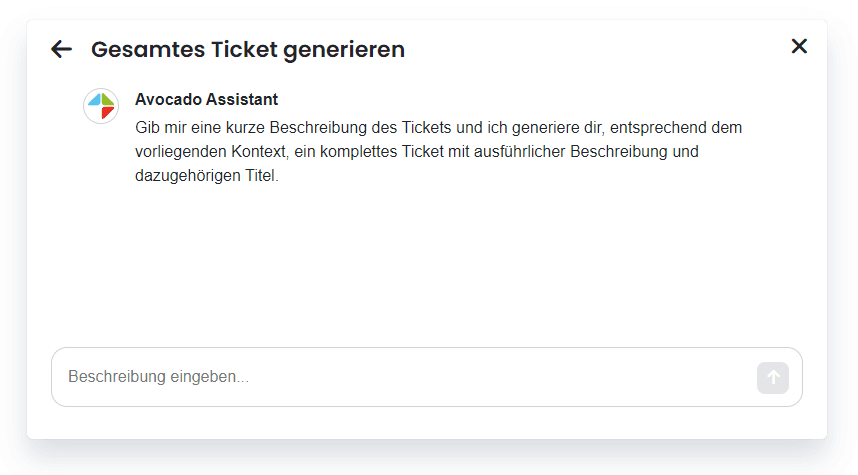
Nachdem eine abstrakte Ticketbeschreibung formuliert wurde, wird der Input an das Backend gesendet, um das entsprechende Modell anzusprechen. Um eine nahtlose Benutzererfahrung zu gewährleisten, erfolgt die Response direkt als Stream. Dadurch wird der Text automatisch aktualisiert, ohne dass ein separater Ladebalken erforderlich ist. Dies ermöglicht es, den Generierungsprozess zu beobachten, während der Text fortlaufend erstellt wird.
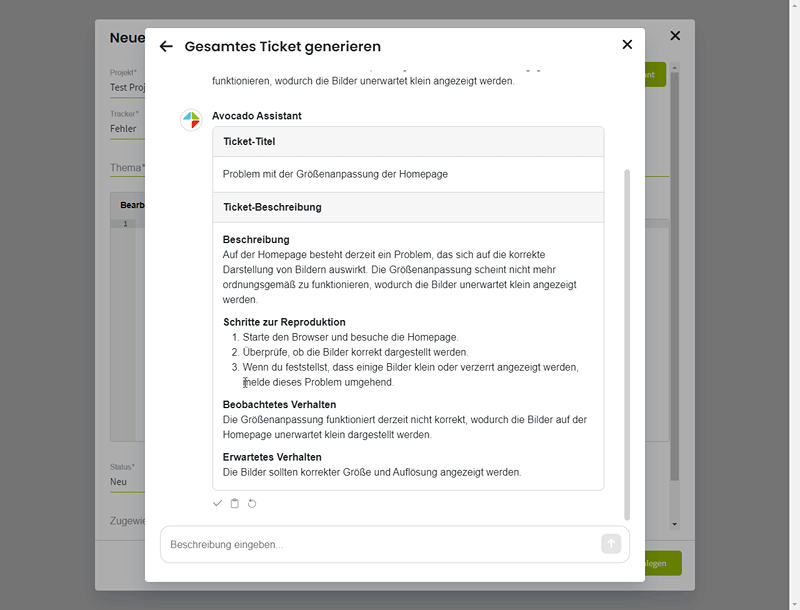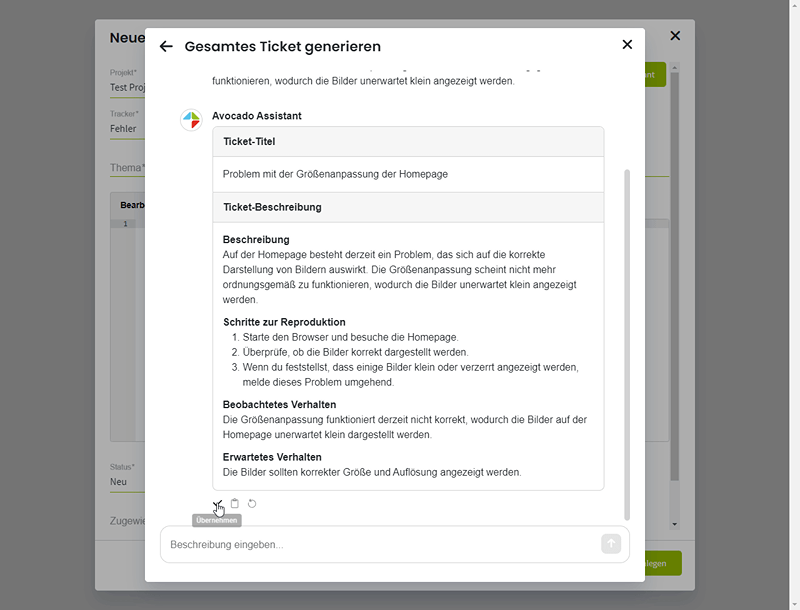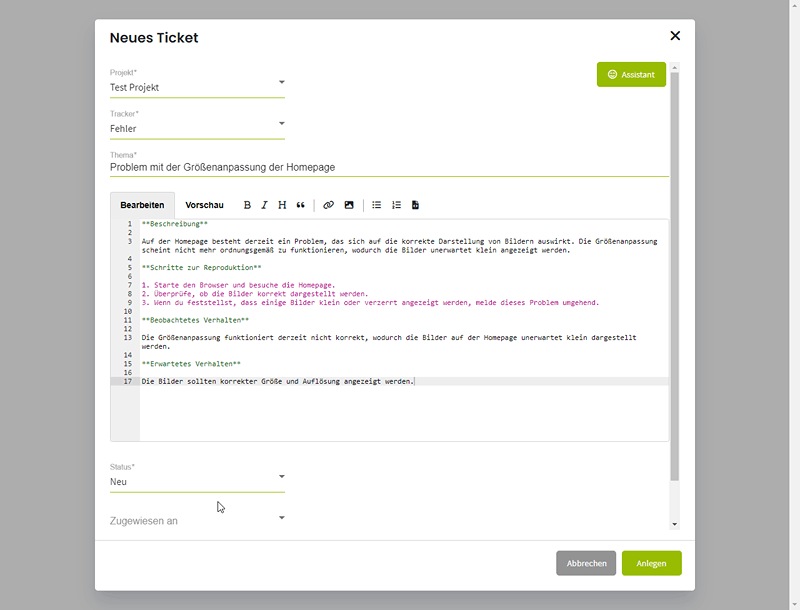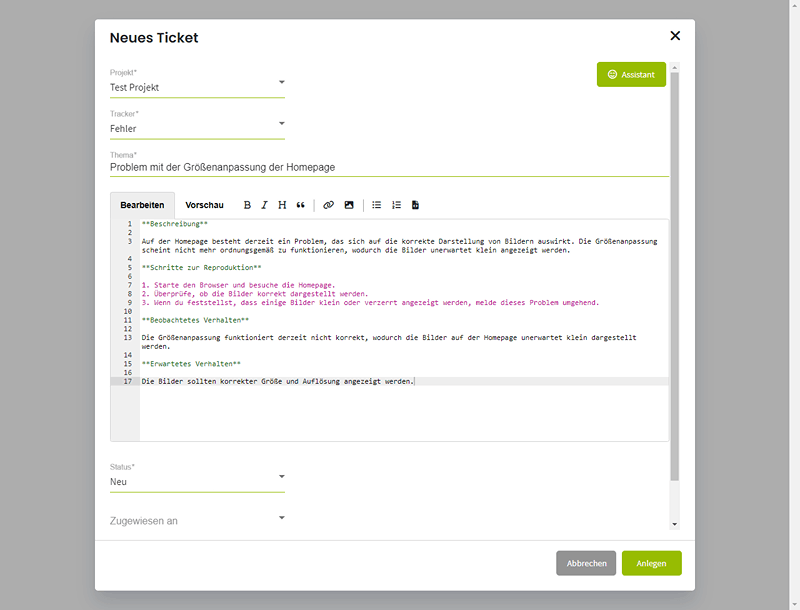
Ergebnis in Markdown-Editor importieren
Nachdem man mit dem generierten Ergebnis zufrieden ist, besteht die Möglichkeit, den Output direkt in den Markdown-Editor des Ticket-Erstellungs-Modals zu importieren. Dies ermöglicht eine nahtlose Übernahme des erstellten Textes in die Ticketbeschreibung, ohne dass zusätzliche Schritte erforderlich sind.
Fazit
Die Einbindung künstlicher Intelligenz in das Projekt ermöglichte mir eine vielschichtige und lehrreiche Erfahrung. Durch die Nutzung von KI-Technologien wurde ein innovativer Ansatz verfolgt, um bestimmte Aufgaben im Projektmanagement zu automatisieren. Die Anwendung von KI ermöglichte nicht nur die Automatisierung, sondern eröffnete auch neue Perspektiven für effiziente und präzise Lösungen.